Great big examples
Normally it's useful to give a simple example of something when you're trying to explain it. But sometimes it's good to give a great big example instead.
I first noticed this back in university when I was helping a friend learn how to use the chain rule in calculus, filling in a gap in the slightly rubbish maths teaching he’d had in secondary school. The example we’d had in class was something like \(\sin(2x)\), and I had a hunch that he just needed to see MOAR CHAIN RULE to understand what was going on, so instead I wrote down something like
$$\log\left(\sin\left(\cos\left(\tan\left(2x+3\right)^8\right)\right)\right)$$
and we worked through it in layers. This went brilliantly, and he’d basically nailed the idea two or three layers in. (Obviously this wouldn’t work for everyone! He was confident with maths in general and fast at picking things up, so I was pretty sure I wasn’t going to scare him off with Too Much Chain Rule, and that turned out to be correct.)
Anyway I was thinking about this again the other day when I saw a nice use of a great big example in one of Brady Neal's Youtube lectures on causal inference. Neal is talking about d-separation, a very important concept in causal inference. Roughly, it's a graphical criterion that tells you when one variable is independent of another variable, given that you've conditioned on some other variables. It's fairly intuitive once you understand it, but a bit fiddly to get your head round in the first place as there are a few different cases.
Neal illustrates d-separation with this great big example:
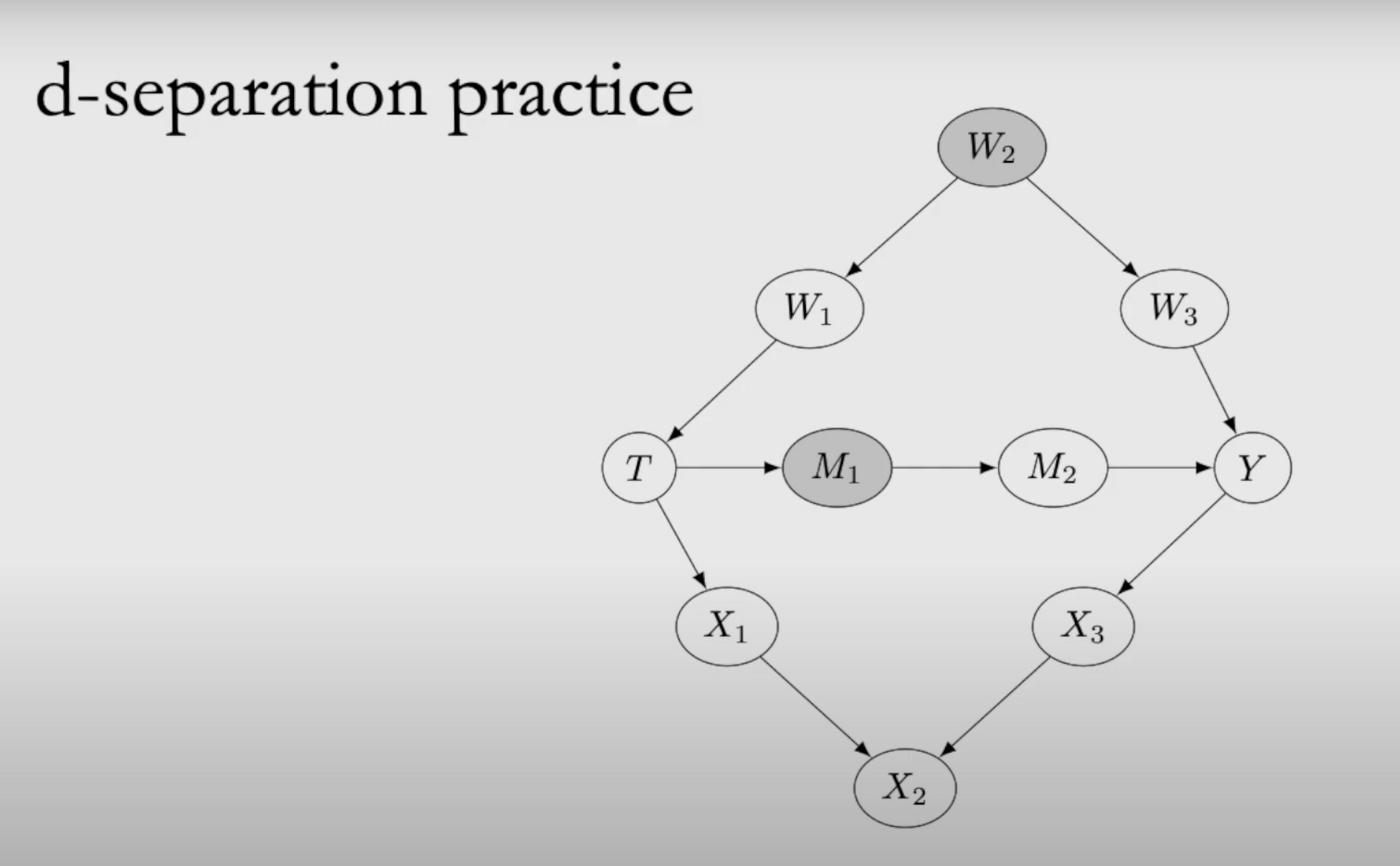
The idea is to work out whether the variables \(T\) and \(Y\) are d-separated, given conditioning on various other nodes in the graph. For example, in the screenshot above he's conditioning on \(W_2\) and \(M_1\), shown in grey. It's a big enough graph that there are lots of options for nodes to condition on, and working through a bunch of different choices gives a lot of intuition for d-separation.
One more example. Git has some notation for parents of commits that I’ve mostly been able to ignore, but once I actually needed it and was confused by what the ~s and ^s were doing. This was solved by the great big example in this Stack Overflow answer (taken from the git rev-parse documentation):

It’s good enough that I didn’t really need to read the text of the answer! (I’ve called this pattern “examples only” in some previous thoughts about exampleology.)
Now I'm looking at these three examples and seeing whether they help me understand when a great big example is the right choice. It seems to be good for practice with some fairly mechanical computation method, rather than conceptual understanding. For example, the chain rule example is about how to compute with the chain rule; it doesn't tell you anything about why the chain rule works. A great big example makes it harder to retain conceptual meaning, because it's just too big to keep in your head at once, but also it's big enough to provide a lot of computational practice, which is exactly what you need sometimes.
In some ways a great big example is just a collection of many small examples. This is particularly obvious in the git example, which lists the small examples that make it up at the bottom, but you can see it in all three. It somehow seems better than many small examples, though. I think this is because you only pay one upfront cost of loading in the context, but there may be other advantages too.
I'd be interested in more thoughts on when this pattern works, or other good examples of great big examples.